DeepSeek V3 Bullet Points
This blog is about the bullet points I summarized after learning the technical report and source codes of DeepSeek V3. It is a really amazing and resourceful process.
Network
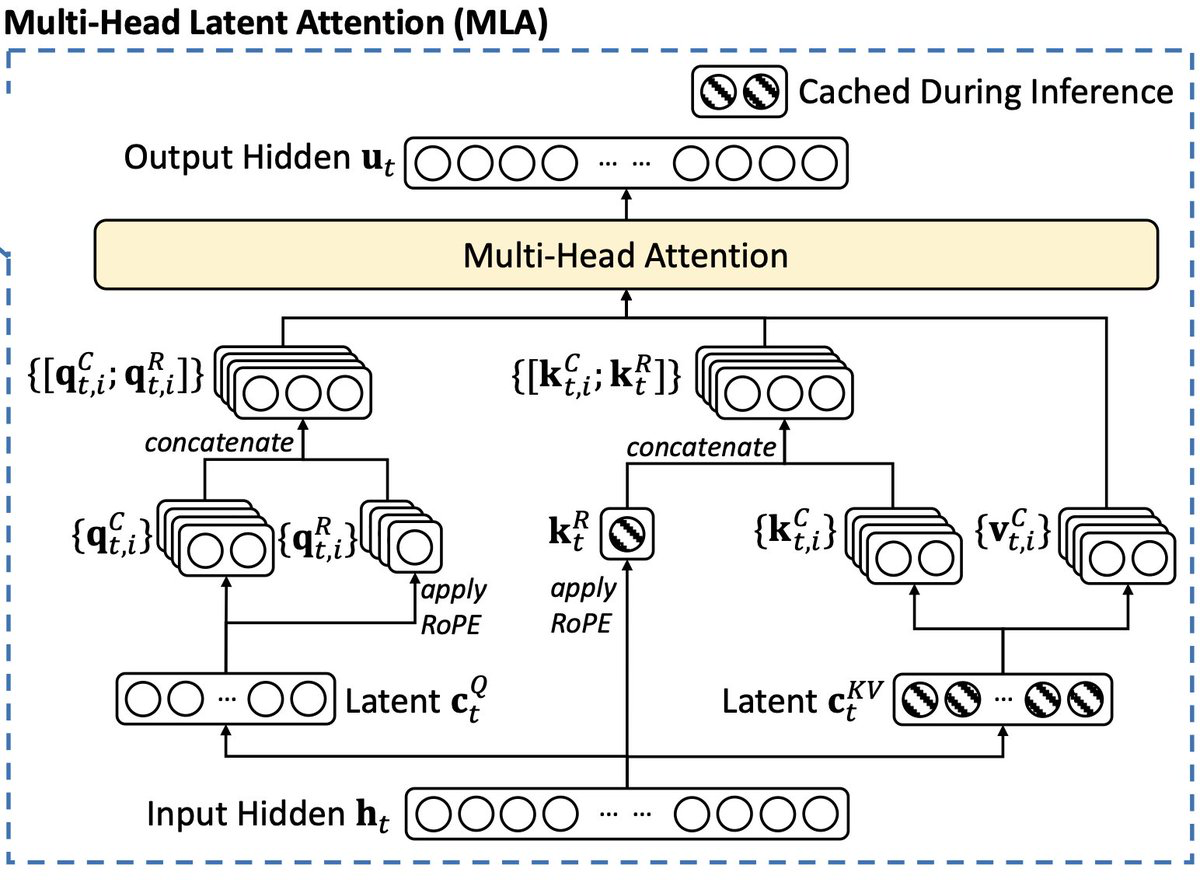
Multi-head Latent Attention (MLA)
- K, Q and V are first down-projected to a much lower latent dimension and then up-projected to original dimension.
- KV cache only needs to save the latent features of history KV.
- It creates a separate vector for K and Q to encode Rotary Positional Embedding (RoPE)
Attention scaling
- When sequence length exceeds the training sequence length, attention scaling is needed to prevent attention from becoming too diffuse over longer sequences, so that the model is able to focus on relevant tokens more.
- It is like temperature controlling.
- DeepSeek applies this to context extension after the pre-training stage. And it performs two additional training phases, each comprising 1000 steps, to progressively expand the context window from 4K to 32K and then to 128K.
- The scaling multiplies the attention scores by a factor larger than one, so that the probability distribution after softmax will be shaper.
- \[\text{softmax} \left( \frac{\mathbf{q}_m^T \mathbf{k}_n}{t \sqrt{|D|}} \right)\]
- \[\sqrt{\frac{1}{t}} = 0.1 \ln(s) + 1\]

Mixture of Expert (MoE)
- MoE is mainly applied to FFN module. It can have a list of FFN networks each of which is called an expert.
- Some of the experts are shared (always active), some of them called route experts are not. Their outputs are summed together with inputs (skip connection).
- Each route expert has a learnable vector. Similarity scores is computed by a linear layer combined with softmax. Only top-K similar route experts will be activated in the FFN computation.
- Sparse model instead of dense. It can increase the capacity of transformer (more FFN) while keeping the computation and memory fixed (top-K).
- DeepSeek-V3 has 671B total parameters while only 37B are active.
- It also makes pre-training much faster.
Load balancing
- The gating function assigns each token to the most relevant experts.
- There could be uneven utilization of experts: some experts are over-assigned, some are never assigned. (Collapse)
- DeepSeek V3 learns a bias term for each expert which is added to the similarity score. It will encourage a more even distribution.
- For any training sequence, there is a sequence-wise load balance loss to penalize unbalanced assignment of experts.
SwiGLU for linear layer
- MLP of DeepSeek is computed as
self.w2(F.silu(self.w1(x)) * self.w3(x)). F.silu(self.w1(x)) * self.w3(x)is the mechanism of Swish-Gated Linear Unit. The SiLU activation outputF.silu(self.w1(x))serves as the gate controlling the flow of information of linear layerself.w3(x).
Network params
- 61 transformer blocks
- Feature dimension = 7168
- KV low-rank dimension = 512
- Query low-rank dimension = 1536
- Each MoE layer consists of 1 shared expert and 256 routed experts, where the intermediate hidden dimension of each expert is 2048. Among the routed experts, 8 experts will be activated for each token.
- 671B total parameters, of which 37B are activated for each token
Infrastructure
Parallelism
- Data Parallelism (sharded memory)
- 16-way Pipeline Parallelism
- 64-way Expert Parallelism (Mixture of experts)
- “We leverage pipeline parallelism to deploy different layers of a model on different GPUs, and for each layer, the routed experts will be uniformly deployed on 64 GPUs belonging to 8 nodes.”
- Parallel embedding is usually used to divide a large vocabulary size across multiple nodes. The embedding is a large tensor of shape [vocab_size, embed_dim].
- In DeepSeek V3, the implementation is this: for the input that contains a list of token ids, they will be broadcasted to all nodes. If a token id can be found in the local vocabulary, it will return the embedding, otherwise it will be all zeros. The returned embeddings will be summed by
all_reduce().
- In DeepSeek V3, the implementation is this: for the input that contains a list of token ids, they will be broadcasted to all nodes. If a token id can be found in the local vocabulary, it will return the embedding, otherwise it will be all zeros. The returned embeddings will be summed by
Mixed Precision
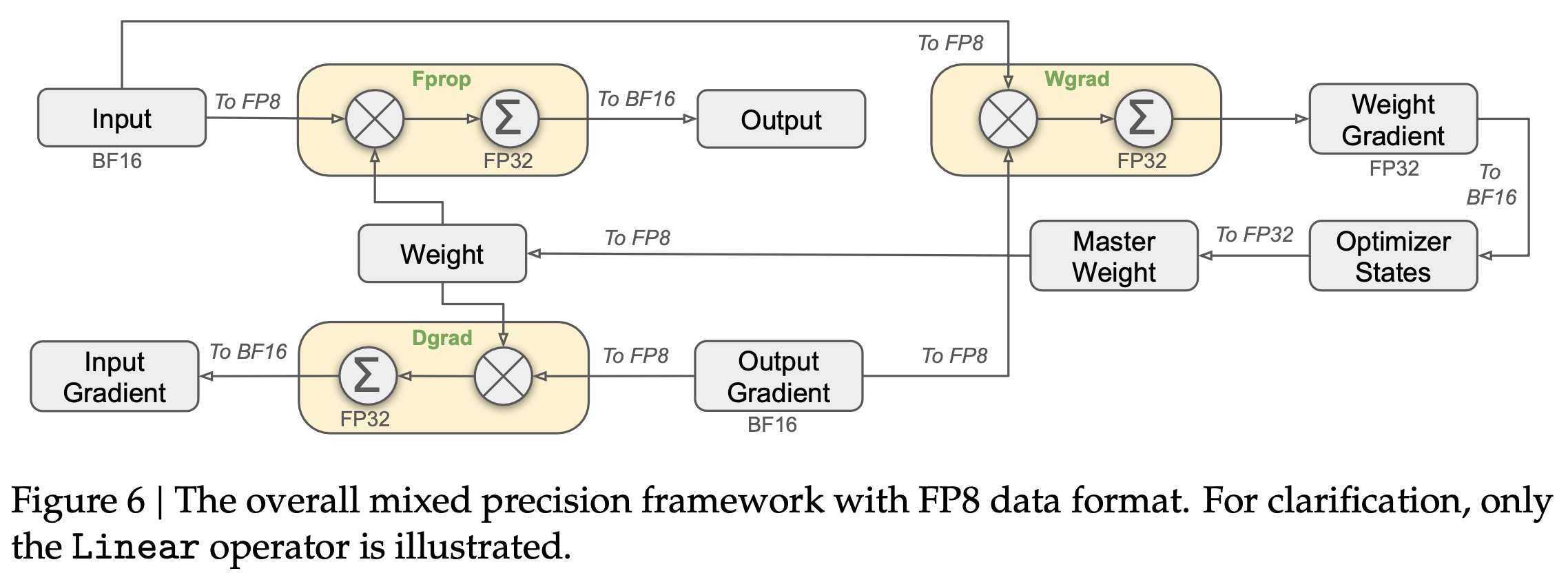
Below is an example of mixed precision training applied to Linear operator. Some keypoints are:
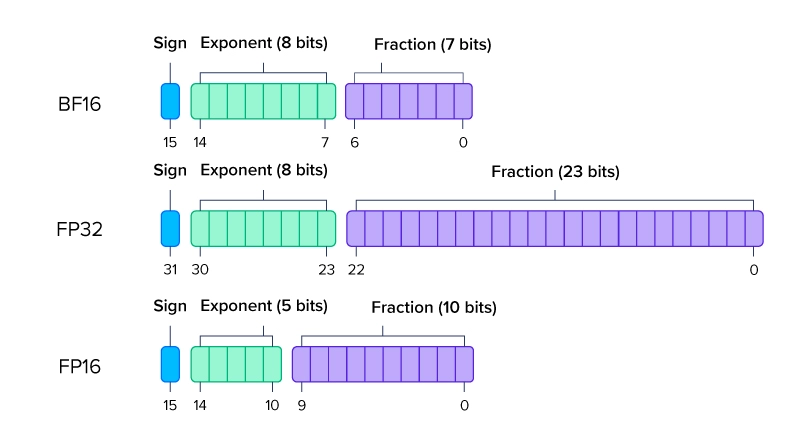
- Float point: sign bit + exponent + fraction/mantissa
- BF16 v.s. FP32 v.s. FP16
- Gradients and optimizer states must be computed as BF16 or FP32 to ensure sufficient range for numeric stability. After the gradient update, the parameters can be casted to FP8.
- All GEMM operators are like black boxes. They cast all input tensors to FP8 and cast all output tensors back to FP32 or BF16. It will save memory bandwidth and improve computational efficiency.
- For all the parameters (like weight), there is a high-precision copy of them (like master weight). The gradient updates are performed over high-precision copy and the low-precision copy is casted from the high-precision copy.
- Some operators still have to use high precision due to their sensitivity to low-precision computations.

How to handle overflow and underflow
- Overflow
- Per-group scaling: DeepSeek V3 rescales the maximum absolute value of the input tensor and weights (in smaller groups) to the maximum representable value of FP8. It is more robust to outliers than scaling with the maximum absolute value of a whole tensor. It is to prevent overflow.
- Underflow
- Gradient scaling: Gradients are first upscaled and then downscaled right before updating the weights. It is to prevent underflow.
Pre-training
Tokenizer
- Byte-level BPE, vocab size = 128k
Training data
- Enhance the percentage of mathematical and programming samples
- 14.8T high-quality and diverse tokens
Fill-in-Middle (FIM) strategy
- Goal: enable the model to accurately predict middle text based on before- and after- contextual cues
- It formulate the training sequence as
<|fim_begin|>f_pre<|fim_hole|>f_suf<|fim_end|>f_middle<|eos_token|>, where<|fim_begin|>,<|fim_hole|>,<|fim_end|>and<|eos_token|>are special tokens.f_pre,f_sufandf_middleare texts. It moves middle text to the end of the sequence so that they can be predicted based on the attention with prefix and suffix texts. - Applied at document level at a rate of 0.1
Learning rate scheduling
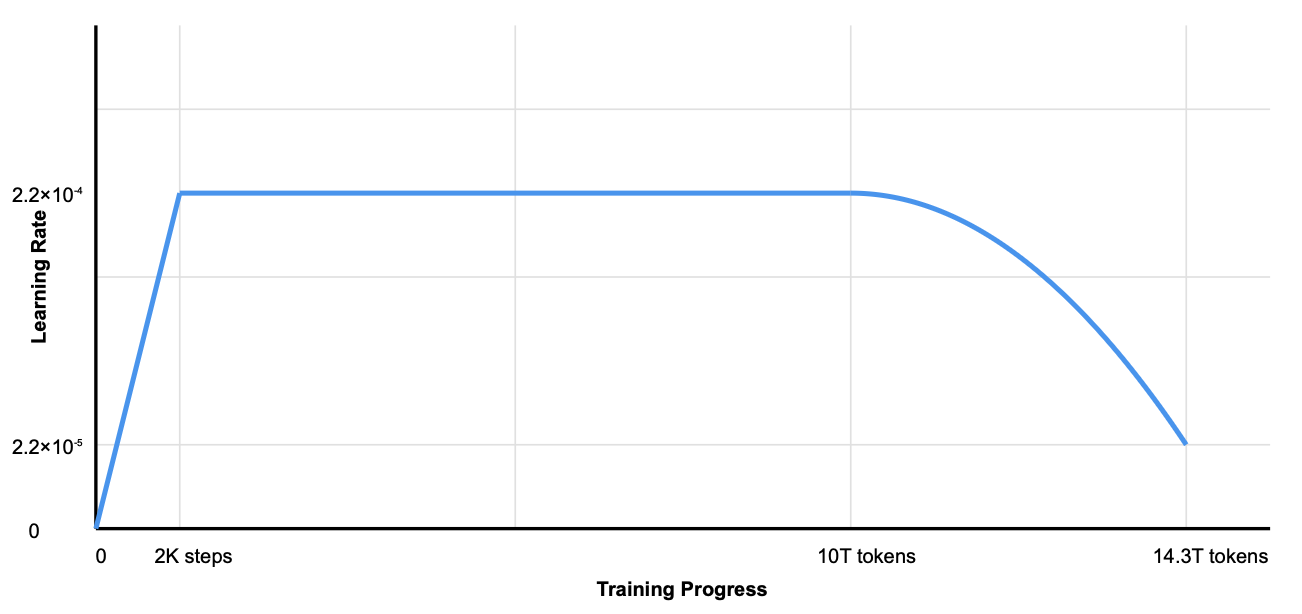
- We first linearly increase it from 0 to 2.2 ×10−4 during the first 2K steps. Then, we keep a constant learning rate of 2.2×10−4 until the model consumes 10T training tokens. Subsequently, we gradually decay the learning rate to 2.2 ×10−5 in 4.3T tokens, following a cosine decay curve.
Long context extension
- After pretraining above, 2 phases of context extensions are applied to extend context length from 4K to 32K, and then to 128K. Each phase has 1000 steps.
- Attention scaling is applied (based on paper YARN) to make the probability distribution of softmax attention sharper for long contexts.
Post-training
More post-training techniques are included in DeepSeek-R1.
Supervised finetuning
- DeepSeek curated instruction-tuning datasets including 1.5M data points spanning multiple domains, such as coding, mathematics, reasoning, writing and role-play…
- Each data point is like
- Instruction: “Summarize this paragraph about climate change…”
- Input: [the actual paragraph text]
- Expected Output: [the correct summary]
Reinforcement learning
- More details can be found in DeepSeek R1. The core is to design reward models.