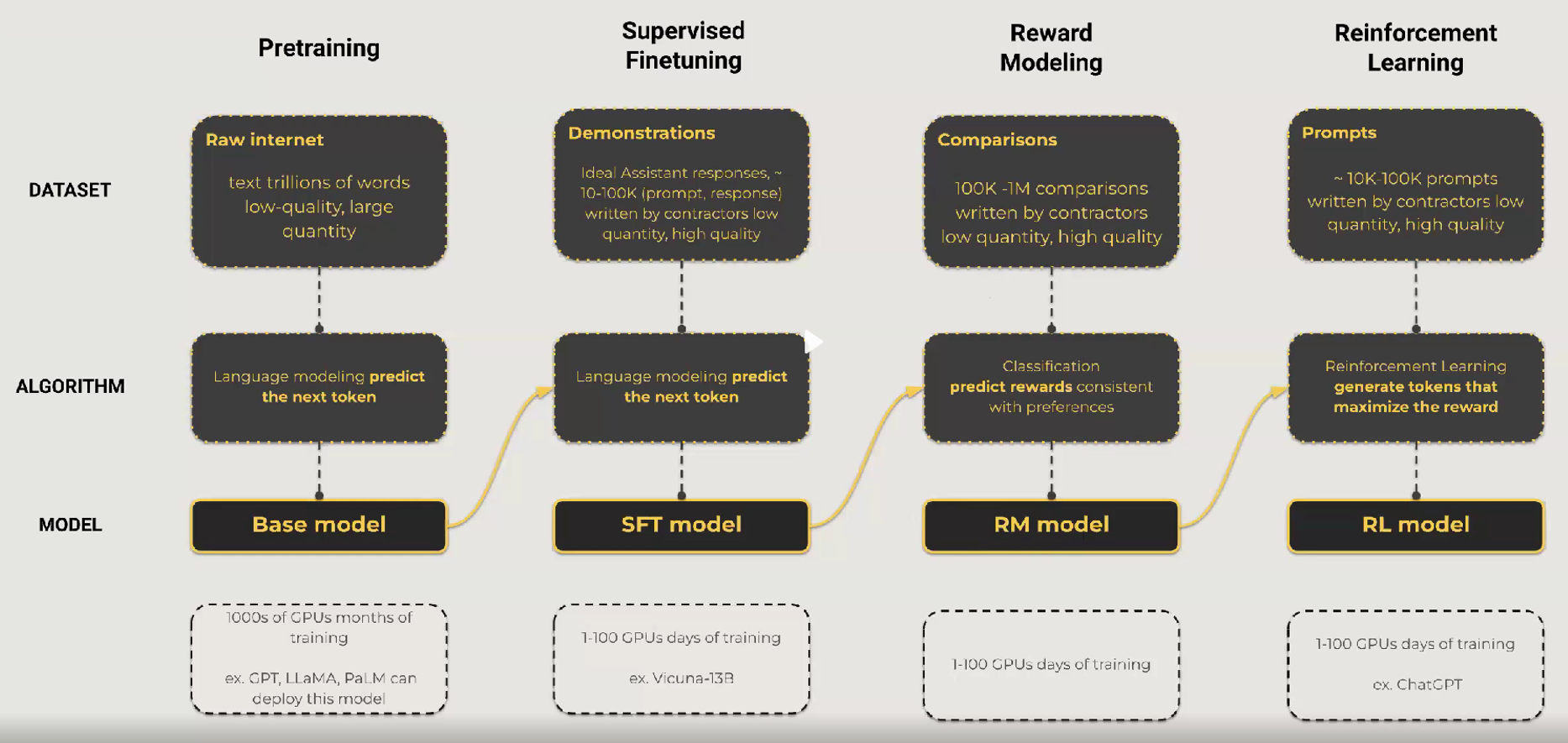
What Can We Learn from LLM? Train a model to train a model
Data Collection & preprocessing
Gold in gold out
Quality & Accuracy (Noise, outliers, errors, inconsistency & incoherence, biases) Filtering/curation/cleaning/Profanity or sensitive info or toxicity check
Scale & diversity (De-duplication) Catogorization (Summarization, Q&A, Codes, Math, Languages, table, charts, numbers, PDF, email) Sentiment classification Topic classification
Data augmentation
Unified format, e.g., JSON format
Structuring e.g., pairs for Q&A tasks
Tokenization
Learn patterns and relationships Improve generalisation to new data samples