What Can We Learn from LLM? Versatility
Recent advancements in multi-modality neural networks reflect a clear trend in network design, as observed from GPT-2 to GPT-4: networks are becoming increasingly simpler, more unified, and end-to-end, with less human-injected inductive bias. Crucially, these networks are now far more versatile, capable of accepting and producing various forms of input and output, and performing multiple tasks simultaneously.
The versatility of a single network grows exponentially rather than linearly with the number of tasks it can handle. This is because a “job” often comprises multiple tasks of varying complexity. Ideally, the number of jobs a network can perform is expressed as \(N_{jobs} = 2^{N_{tasks}} - 1\). This exponential growth in capability is fueling optimism about achieving Artificial General Intelligence (AGI). If a network can perform as many tasks as a human, there will be little reason to deny the arrival of AGI.
Here are some groundbreaking papers I’ve reviewed that highlight these trends:
- MovieGen for video generation
- PaliGemma for vision-language reasoning
- Moshi for conversational AI
- OCR 2.0 for OCR tasks
- EMMA for autonomous driving
These networks unify input/output formats and streamline similar subtasks within their domains using techniques that I’ll explore below.
Tokenize Everything
The first step to building a versatile network is ensuring compatibility with various data modalities and formats. Humans process data in numerous forms—text, images, video, audio, and more—often without recognizing its diversity. Similarly, recent models tokenize these data types, converting them into a universal “language” that transformers can process, understand, and learn from.
Modality-Specific Tokenization
Each data modality has its unique tokenization approach:
- MovieGen controls output video FPS by using text tokens like “FPS-16.”
- PaliGemma employs 1,024 location tokens for normalized image coordinates of bounding boxes and 128 mask tokens for segmentation.
- Moshi encodes audio segments as tokens using a neural audio codec.
- EMMA uses plain text tokens, even for representing waypoint coordinates.
Some tokenizers, like SentencePiece for text, are manually designed, while others, such as those for speech, images, and videos, are learnable. Notably, tokenizer efficiency significantly impacts model performance. For instance, the Llama 3 technical report highlighted a substantial performance boost from improved tokenization.
Positional Embedding for Structured Data
Since most data has structure, positional embeddings are used to encode the spatial or temporal relationships of tokens. This is particularly critical for higher-dimensional data:
MovieGen learns separate embeddings for spatial dimensions (H, W) and the temporal dimension (T). 3D tasks utilize specialized embeddings, such as Plücker coordinates for encoding camera rays, or learn camera intrinsic embeddings via linear layers. As tokenization continues to advance, it’s foreseeable that all analytical signals and sensory information could be tokenized and interconnected through transformer attention mechanisms. This process resembles a compiler translating human-understandable information into a format comprehensible by neural networks.
Multi-Tasking and End-to-End Learning
Modern multi-modality networks stand out for their multi-tasking capabilities and end-to-end frameworks. These characteristics mark a significant leap in versatility compared to earlier single-task methods.
Unified Task Formulation
Tokenization allows many tasks to be reformulated as “predicting the next token.” This enables networks to handle different tasks in a single forward pass and train them simultaneously in a single backward pass. Analogous to the human brain, different neurons are activated by different tasks without altering the overall architecture.
- Cross-Domain Training: Networks like OCR 2.0 are trained on diverse datasets, combining plain OCR data with math and molecular formulas, tables, charts, sheet music, and geometric shapes.
- Multi-Objective Training: Similar to students taking courses in multiple subjects, networks like PaliGemma combine tasks such as captioning, QA, OCR, detection, and segmentation during training.
The End-to-End Advantage
End-to-end architectures demonstrate superior scalability and generalization compared to pipeline approaches. For example:
- Traditional OCR systems rely on a sequence of networks (layout analysis, text detection, region extraction, content recognition), where the weakest link can bottleneck performance.
- OCR 2.0, in contrast, employs an end-to-end framework capable of generalizing across tasks and improving as more data becomes available.
End-to-end systems eliminate intermediate bottlenecks, simplify scaling, and enable seamless integration of additional capabilities. This is particularly successful in Full Self Driving (FSD). As uncovered by EMMA, the system can directly map the raw camera sensor data to planner trajectories without any intermediate steps. The network has the poly-intellegence such as spatial reasoning, road comprehension and scene understanding to solve the complex driving task in end-to-end fashion.
Data Strategy & Training Recipe
While the network architecture nowadays becomes very simple, the data strategy and the accompanying training recipe become increasingly complex and rely heavily on experience. It’s like a seesaw: when one side goes down, the other inevitably rises.
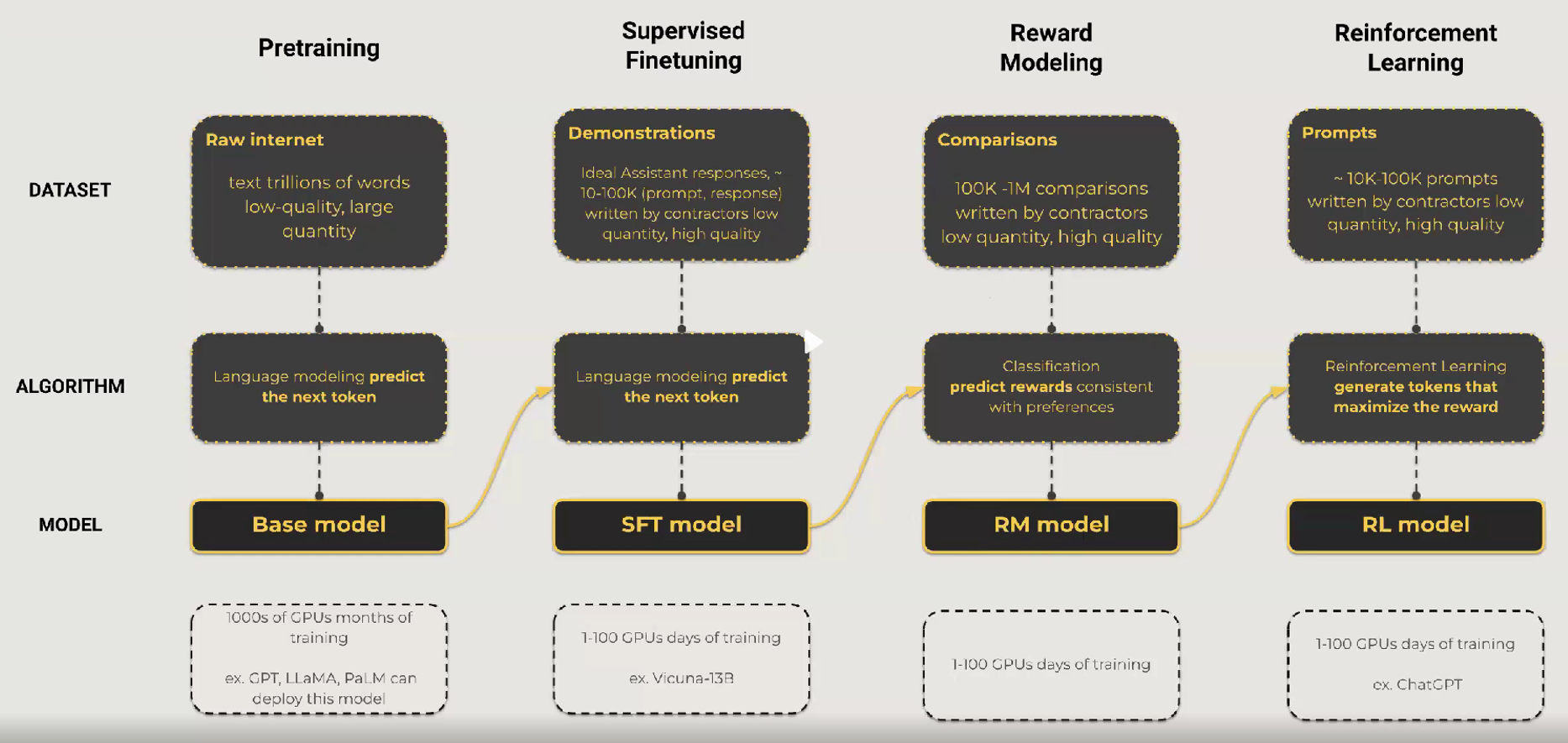
Below chart is an example of the flow of training a LLM. Each step has its own data strategy and training recipe. Pretraining uses a massive amount of raw Internet data through a variety of tasks and advocates the model generalisation through data diversity. Afterwards, supervised finetuning (SFT) uses a small amount of high-quality data to boost the model quality usually within a specific task. Lastly, a reward model is trained to identify good or bad outputs with human feadback to enable reinforcement learning so that the model outputs will be more aligned with human preferences. As you can see, a number of steps are chained together to maximize the quality of the final outputs. Each step requires specific data strategies and training expertises that are also borrowed by training multi-modality neural networks.
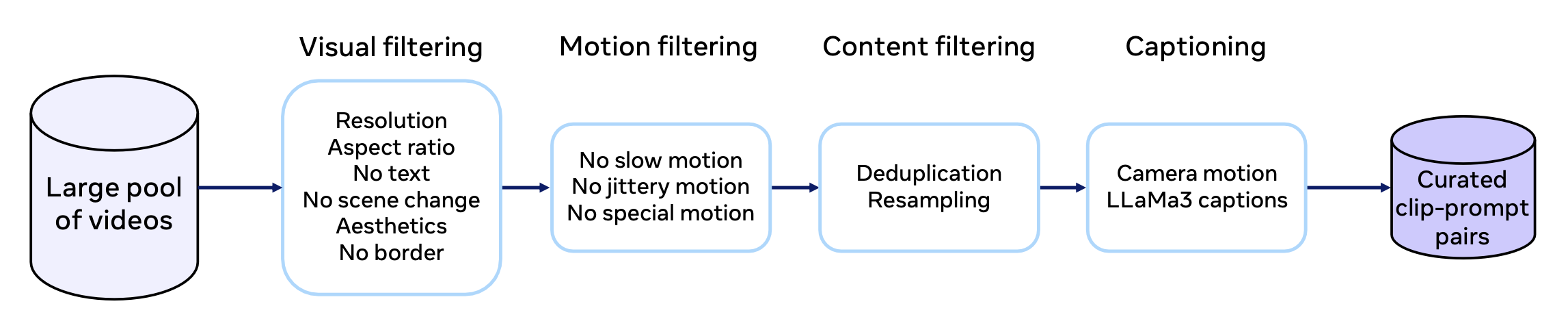
Data quality is equally important. Training a large network nowadays requires an unmatched amount of data compared with before. While the data scale is widely recognized, data quality is equally important as demonstrated by all the papers. A large-scale but contaminated dataset is a worse choice than a smaller-scale but well-curated dataset. It is the logic of gold-in-gold-out. To ensure the data quality, data filtering, curation, cleaning, deduplication, resampling and toxicity checking are all necessary. In MovieGen, the details of filtering video data has been revealed in detail. It has a visual filter to avoid texts and scene changes, a motion filter to remove static or jittery cameras and a content filter to do deduplication and resampling.
Coarse-to-fine training. All the large models follows the coarse-to-fine training process. The networks are usually first trained by low-quality raw data as warm-up or pre-training and then finetuned by high-quality data. For visual data, it is a coarse-to-fine process from low resolutions to high resolutions. There are a few reasons. First, coarse-level data is much larger in amount than fine-level data. Training that starts from large-scale coarse data will avoid overfitting to a small corpus and encourages generalisation of the networks. Second, generating low-quality data by a generative model is much easier than generating high-quality data. Generating Shakespeare is hundred times more challenging than generating a reddit user. Therefore gradually increasing the difficulty by controlling the training data quality has the benefits of stablizing the network learning. Lastly, as shown by Dino-v2, pretraining with low-resolution data and then finetuning with high-resolution data is much more efficient than training with high-resolution data alone. It not only leads to comparable model performance but also reduces the time, computational and memory costs by several times.
Knowledge distillation from low dimension to high dimension. There is a noticeable and understandable practice that when training a multi-modality model that involves high-dimensional data, it naturally borrows the knowledge from the models trained with corresponding low-dimensional data. For example, training a video diffusion model depends a lot on an image diffusion model. It also applied to 3D or 4D tasks. A 3D object generation task depends on a video generation model to pre-generate multiview consistent frames. A model that aligns multiple modalities also depends on the models trained on unimodal data and then simply learns a projector, e.g., PaliGemma. The reasons are understandable. First, low-dimensional generation tasks can be seen as a sub-task of high-dimension tasks. An images is just a single frame of a video. Thus low-dimensional models can be naturally adapted to high-dimensional models. Second, the high-dimensional data is much rarer than low-dimensional data. MovieGen has O(1)B image-text pairs but O(100)M video-text pairs in its training data. The number of the available 3D models are only in millions, which is smaller than images and videos by many orders of magnitudes. Multimodal coherent data is also much fewer than single-modal data. As said in Moshi, a single-stream audio data is in 7M hours, while multi-stream conversation data is only 2000 hours. Due to the data scarcity, leveraging the prior knowledge from the pre-trained low-dimension models and data is sensible.