How does KinectFusion work?
- Overall System Workflow
- Measurement
- Pose Estimation
- Update Reconstruction
- Surfact Predicition
- Reference
Overall System Workflow
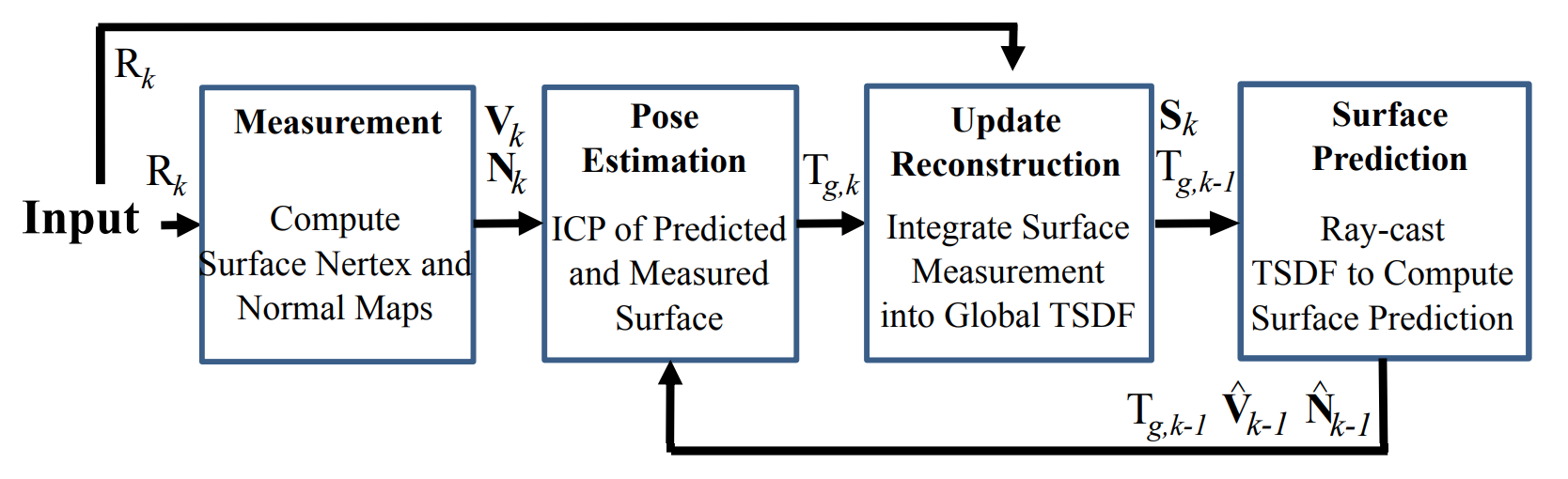
KinectFusion是一个完全基于深度图的SLAM系统,输入是深度图流,输出是每帧深度图的pose和基于TSDF技术的mapping(as surface reconstruction)。工作流程主要分为四个模块:
Measurement
这一步对输入的raw depth measurements进行预处理,计算出每个pixel在相机坐标系下的三维坐标和normal, 即\((\mathbf{V}_k^c, \mathbf{N}_k^c)\)。注意,在计算normal map之前会对raw depth map进行bilateral filtering,以得到更高质量的normal结果。
Pose Estimation
因为输入是连续的深度图流,所以估算下一帧的相机pose其实就是做tracking。方法是将当前帧的点云通过ICP算法align到上一帧的点云(或已重建出的全局surface)上。注意,此处用的error metric是point-plane distance,即两点连线在法线方向的投影的长度。在找correspondence时需要保证两点的距离和法线的夹角都要小于阈值。ICP初始化时,用上一帧的pose来初始化当前帧。在ICP优化的迭代过程中,可以合理地假设每步更新的旋转角很小,因此对两帧之间的relative transformation进行如下参数化:
\[\mathbf{T}_{inc} = [\mathbf{R} \| \mathbf{t}] = \begin{bmatrix} 1 & \alpha & -\gamma & t_x\\ -\alpha & 1 & \beta & t_y \\ \gamma & -\beta & 1 & t_z \end{bmatrix},\]即优化6维变量\(\mathbf{x}=(\beta, \gamma, \alpha, t_x, t_y, t_z)^T\)。
在第\(n\)步迭代时,全局坐标系下点云坐标的更新表达为:
\[{\mathbf{V}_k^g}^{(n)} = \mathbf{R} {\mathbf{V}_k^g}^{(n-1)} + \mathbf{t} = \mathbf{G} \mathbf{x} + {\mathbf{V}_k^g}^{(n-1)},\]此处,\(\mathbf{G}=\left[ [{\mathbf{V}_k^g}^{(n-1)}]_{\times} \| \mathbf{I}_{3\times3} \right]\)。这样一来,error fuction就变成关于\(\mathbf{x}\)的线性函数。在每一步迭代更新都变成一个convex least square问题,只需将derivative设为0,求出\(\mathbf{x}\)的最优解即可。
一旦tracking失败,例如相邻两帧motion过大导致不能用上一帧的pose初始化当前帧(判断tracking是否失败的方法详见论文),将不得不做relocalization。KinectFusion用交互的方式手动进行重定位。
Update Reconstruction
当估算出新的一帧的pose之后,就要用当前帧的信息对基于TSDF的volumetric reconstruction进行更新。首先,在全局坐标空间中放置了一组\(512\times512\times512\)(举例)的voxel grids。TSDF的原理就是,对于每一帧由深度图产生的点云,我们对每一个voxel计算一个TSDF的值以及一个weight权重,即\((F_k, W_k)\)。TSDF值表示的是某个三维空间中的点在该相机坐标系中的深度与它的投影的深度值\(depth\)的差(带符号,truncated)。如果该点正好落在surface上,那么两个深度值应该相等,\(TSDF=0\)。权重的计算公式为\(W = \frac{cos\theta}{depth}\)。\(\theta\)表示投影的射线和投影点法线的夹角。若夹角为\(0\),即surface正对着该点,那权重更大,因为这样计算出的TSDF更可靠。\(depth\)越大,深度的误差也越大,所以权重越小。
一个注意点是,做TSDF fusion用的depth map是原始数据,没有经过bilateral filtering处理,按照原文的解释,“The early filtering removes desired high-frequency structure and noise alike which would reduce the ability to reconstruct finer scale structures”。
每当有新的一帧要集成进来时,就会对新的帧算出的TSDF值和原有的TSDF值做加权平均处理。计算方法为
\[F_{:k} = \frac{W_{:k-1}F_{:k-1} + W_{k}F_{k}}{W_{:k-1} + W_{k}},\] \[W_{:k} = W_{:k-1} + W_{k}.\]Surfact Predicition
这一步的任务是从fuse好的存储了TSDF值的voxel grids中估计出surface,即估计出surface上的点的位置和normal。所用的算法是ray casting,即对每一个pixel,沿着射线方向按一定步长marching,一旦相邻两步的TSDF值的符号出现了变化(由正到负为front surface,由负到正为back surface),表明surface点落在其中,通过差值可以计算出更精确的位置。点的normal方向为TSDF的derivative方向,可以理解为在接近surface处,沿着surface方向,TSDF几乎不变(属于zero level set),垂直于surface方向,TSDF变化最大。
Reference
KinectFusion: Real-Time Dense Surface Mapping and Tracking